eclipse中特殊的注释
在eclipse中,TODO、FIXME和XXX等注释都会被eclipse的task视图所收集。
HTML 4 的新特性之一是可以使 HTML 事件触发浏览器中的行为,比方说当用户点击某个 HTML 元素时启动一段 JavaScript.
visibilitychange事件是浏览器新添加的一个事件,当浏览器的某个标签页切换到后台,或从后台切换到前台时就会触发该消息,现在主流的浏览器都支持该消息了,例如Chrome,
Firefox, IE10等。
这个事件可以满足一些用户需求,比如标签页隐藏的时候停止播放音乐视频、停止一些不必要的轮询,还有停止一些诸如轮播等循环动画效果等等。这些可以节省服务器和本地的开销。
前段时间,重新看了一遍电影《肖申克的救赎》……
如果生活是一个牢笼,那么是绝望的等死还是在希望中求生,就是生命是否有意义的差别。
正如主人公安迪所说:Get busy living or get busy dying.
Open API即开放API,也称开放平台。
其中,API,是Application Programming Interface的缩写,是应用编程接口的意思。
所谓的开放API(OpenAPI)是服务型网站常见的一种应用,网站的服务商将自己的网站服务封装成一系列API开放出去,供第三方开发者使用,这种行为就叫做开放网站的API,所开放的API就被称作OpenAPI(开放API)。
作为中文环境下开发的Java程序员,UTF-8编码是我们经常使用的编码方式。
字符编码是怎么来的?为什么使用UTF-8编码?使用字符编码的时候回遇到什么坑?
这些问题你遇到过或者思考过吗。
在显示器上看见的文字、图片等信息在电脑里面其实并不是我们看见的样子,即使你知道所有信息都存储在硬盘里,把它拆开也看不见里面有任何东西,只有些盘片。
假设,你用显微镜把盘片放大,会看见盘片表面凹凸不平,凸起的地方被磁化,凹的地方是没有被磁化;凸起的地方代表数字1,凹的地方代表数字0。硬盘只能用0和1来表示所有文字、图片等信息。
因此,不同的字符在计算机有不同的表示,也就是所谓的编码表。
计算机中存储信息的最小单元是一个字节即8个bit,所以能表示的字符范围是 0~255 个,人类要表示的符号太多,无法用一个字节来完全表示,要解决这个矛盾必须需要一个新的数据结构 char,从 char 到 byte 必须编码。这就是编码出现的原因。
那么字母”A”在硬盘上是如何存储的呢?
可能小张计算机存储字母”A”是1100001,而小王存储字母”A”是11000010,这样双方交换信息时就会误解。比如小张把1100001发送给小王,小王并不认为1100001是字母”A”,可能认为这是字母”X”,于是小王在用记事本访问存储在硬盘上的1100001时,在屏幕上显示的就是字母”X”。也就是说,小张和小王使用了不同的编码表。
为了让大家能够互相理解,大家需要采用统一的编码表。
那么为什么使用UTF-8编码呢?
在所有字符集中,最知名的可能要数被称为ASCII的7位字符集了。它是美国标准信息交换代码(American Standard Code for Information Interchange)的缩写, 为美国英语通信所设计。它由128个字符组成,包括大小写字母、数字0-9、标点符号、非打印字符(换行符、制表符等4个)以及控制字符(退格、响铃等)组成。但是,由于他是针对英语设计的,当处理带有音调标号(形如汉语的拼音)的亚洲文字时就会出现问题。
Unicode(统一码、万国码、单一码)是计算机科学领域里的一项业界标准,包括字符集、编码方案等。Unicode 是为了解决传统的字符编码方案的局限而产生的,它为每种语言中的每个字符设定了统一并且唯一的二进制编码,以满足跨语言、跨平台进行文本转换、处理的要求。1990年开始研发,1994年正式公布。Unicode 只是一个符号集,它只规定了符号的二进制代码,没有规定这个二进制代码应该如何存储。
互联网的普及,强烈要求出现一种统一的编码方式。UTF-8 就是在互联网上使用最广的一种 Unicode 的实现方式。其他实现方式还包括 UTF-16(字符用两个字节或四个字节表示)和 UTF-32(字符用四个字节表示),不过在互联网上基本不用。
UTF-8 最大的一个特点,就是它是一种变长的编码方式。它可以使用1~4个字节表示一个符号,根据不同的符号而变化字节长度。
上面介绍了字符编码的一些知识,下面针对实际应用中遇到的两个问题的解决进行分析。
BOM是Byte order mark的缩写,一般作为标识出现在文本的首行。
因为在Windows平台下,默认不显示BOM,因此在读取文件、编译源码或者执行SQL的时候,很可能因为文件是UTF-8 BOM格式的,而产生错误。
例如简单的Test.java:
1 | public class Test{} |
如果保存为UTF-8 BOM格式,在编译的时候回出现如下错误:
1 | # javac Test.java |
这就是因为文件是以Byte order mark开头导致的。
这种问题一般是怎么出现的呢?一般是由于在不同平台(例如Windows和Linux之间)、不同编辑器(例如邮件编辑、文本编辑)之间互相传文件造成的。
那么如何避免这个问题呢?答案就是通过编辑器仔细检查编码,或者用批量替换、过滤的方式,避免出现这种字符。
控制字符(Control Character),出现于特定的信息文本中,表示某一控制功能的字符。
但是控制字符不能再XML中自由的转换,如果XML的内容出现了控制字符,会出现Unmarshalling Error。
例如将一段用户输入的地址数据,通过Webservice接口传输的过程中,出现了如下异常,就是控制字符造成的:1
2
3
4
5webservice exception,
error message:
{}\norg.apache.cxf.binding.soap.SoapFault:
Unmarshalling Error:
Illegal character ((CTRL-CHAR, code 8))\n at [row,col {unknown-source}]: [201,32] \n\tat
简单的解决办法就是将控制字符进行转换:
1 | return CharMatcher.JAVA_ISO_CONTROL.removeFrom(string); |
1 | string.replaceAll("\\p{Cntrl}", ""); |
1 | StringEscapeUtils.escapeXml10(string); |
EL(Expression Language) 是为了使JSP写起来更加简单。表达式语言的灵感来自于 ECMAScript 和 XPath 表达式语言,它提供了在 JSP 中简化表达式的方法,让Jsp的代码更加简化。
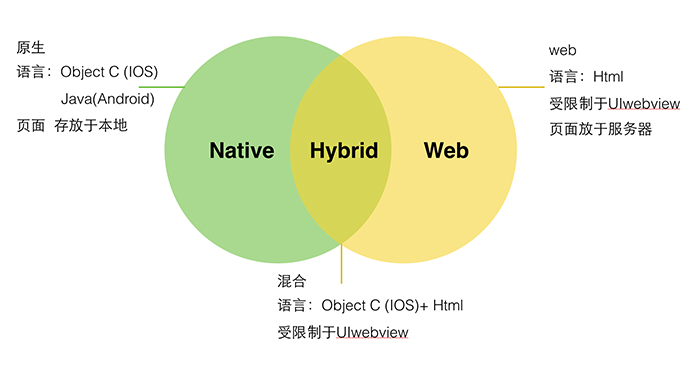
在PC时代,有C/S模式(又称Client/Server或客户/服务器模式)和B/S模式(又称Browser/Server或浏览器和服务器模式)之争,而在移动应用时代,APP开发模式通常分为Web APP与Native APP原生模式两种。
这两种模式均各自有自己的优势,到底是采用Native App开发还是采用Web App开发一直是业界争论的焦点,但是随着HTML5的发展及云服务普及,采用HTML5进行Web App开发正在成为一种趋势,用户可以根据应用特点和需求进行选择,亦可选择两者混合模式(Hyprid App)。
下面分别对Native App、Web App和Hybrid App 进行详细介绍,让你对这几种开发模式有深入的了解。